MySQLを使用しているWebアプリにて、DBのパフォーマンス調査と改善に関する作業を行いました。
その時の作業に関する備忘録としてまとめた記事になります。RDSのMySQLでパフォーマンス改善を検討する場合の参考になれば幸いです。
スロークエリの設定
アプリケーションの動作が遅くなっている場合、まずはボトルネックがどこにあるのかを切り分けることが重要です。
Webアプリケーションの場合、動作が遅くなる原因としてフロントエンド、バックエンド、ネットワーク遅延、DB設計、SQLなど様々な原因が考えられますが、扱うデータ件数が多い場合、DBアクセスがボトルネックになっているケースは少なくありません。
MySQLの場合、DBの設定によりスロークエリログを出力することができます。スロークエリ(実行に時間がかかっているSQL)を確認することで、DBに原因があるのかどうかの切り分けができると共に、改善の余地があるSQLを確認することができます。
スロークエリの設定をするには、以下のパラメータを変更します。
slow_query_log:スロークエリの有効化(デフォルトは無効)long_query_time:何秒を遅いとみなすか
RDSを使用している場合は、パラメータグループから設定可能です。
AWS マネジメントコンソール → Aurora and RDS → パラメータグループ → 対象のMySQLインスタンスを選択slow_query_logを1(有効)に設定し、long_query_timeで秒数を設定します。
long_query_timeに関して、何秒を遅いとみなすかはシステムの要件にもよるため、明確な基準はありません。私も調査を始める際にどの程度の秒数が適切か迷ったため、AIと相談したところ、一般的には0.5秒程度から設定して様子を見るケースが多いとのことだったので、そのアドバイスに従い0.5秒を設定して調査を行いました。
ちなみに、本番環境にてスロークエリログを有効にする場合は、ログが大量に出ないように、調査時よりも長めの時間に設定しておく方がおすすめとのことです。調査で0.5秒を閾値にするのであれば、本番環境での運用時は1秒くらいにする方が良いとのこと。この辺りはシステムの要件や性質に合わせて各自調整するようにしてください。
CloudWatchとの連携
パラメータグループの設定をしたらスロークエリのログが出力されるようになります。
スロークエリログはRDSの管理画面から確認することができますが、スロークエリに該当するSQLが多数ある場合、この画面では詳細の確認が面倒です。スロークエリログをCloudWatchに連携することで、CloudWatchのロググループやインサイトから簡単に確認できるようになります。
CloudWatchへの連携の手順は以下です。
インスタンスを選択して「変更」ボタンから変更画面を表示 → 「モニタリング」セクションにて、「ログのエクスポート」のスロークエリログにチェックを入れる → 適用

ログのエクスポートの設定変更は、適用を即座に反映させても問題ありません。これでスロークエリの内容がCloudWatchから参照できるようになります。
スロークエリの原因調査と改善策の考察
スロークエリに対する具体的な対策は原因によって様々です。実行計画を確認しながら、SQLの書き方やインデックス設計を見直したりして検証をします。データの取得件数が多く、SQLやDB設計ではそもそも改善が難しい場合もあります。その場合はアプリケーション全体の設計観点から改善策を検討する必要があります。
この記事では実行計画やインデックスに関する細かい話は割愛します。
今回実際に作業していた中で問題のあったSQLの事例をいくつか紹介し、改善策について考察します。
※サンプルコード内のテーブル名やカラム名は実際のものから変更しています。
use indexが邪魔をしているSQL
今回調査した中で頻繁にスロークエリログとして流れてきたのが以下のようなSQLです。
SELECT
*
FROM
tableA use index(PRIMARY)
WHERE
id <> 'abcdefg'
AND
...tableAはサンプルのテーブル名で、実際のアプリのテーブル名とは異なります。
idカラムがこのテーブルの主キーと考えてください。
ここで出てくるuse index句は、データベースでいうところのヒント句と呼ばれるもので、クエリ実行時に使用されるインデックスを指定するものです。
今回のケースは、このヒント句がSQLの速度を遅くしていました。
MySQLに限らずですが、データベースは内部でオプティマイザと呼ばれる機能を持っており、クエリ実行時に自動的に最適な実行計画を選んで実行してくれています。どのインデックスを使用するのが最適なのか、そもそもインデックスを使用した方が良いのか、そうでないのか、などはオプティマイザが自動で判断してくれます。そのため、通常はヒント句で明示的に使用するインデックスを指定する場面は非常に限られており、頻繁に使うものではありません。私も過去の開発経験の中で1,2回見たことがある程度で、今回の調査で久しぶりにヒント句が指定されているSQLを見ました。
このSQLの一番の問題点は、idの不一致による比較<>をしているにも関わらず、ヒント句で主キーによるインデックスを指定していることです。
通常のインデックス(Bツリーインデックス)は、等号比較=や範囲指定の場合には効果的ですが、<>による比較やあいまい検索では、インデックスが有効に使われないケースが多く、状況によってはフルスキャンの方が高速になることもあります。しかし、今回のケースでは不等号による比較をしているにも関わらず、インデックスの使用を強制していました。そのため、結果としてクエリの実行コストが増え、実行速度が遅くなっています。
まず、DBは内部でオプティマイザによりインデックス使用有無やどのインデックスを使うのが最適化を自動で判断するため、基本的にヒント句(MySQLの場合はuse index句)は使う必要がないことを知っておきましょう。
また、意図的にヒント句を使用する必要性がある場合、どのようなSQLの書き方をすればインデックスが使用されるのかを知っておくことが大事です。
全件取得後に計算結果を比較しているSQL
今回調査をしたアプリでは、対象のデータから物理的に距離が近いデータを取得する機能がありました。
例えば、何かしらのお店を探している際に、お店の詳細ページを表示すると、対象のお店から物理的に距離が近いお店を取得するようなイメージです。
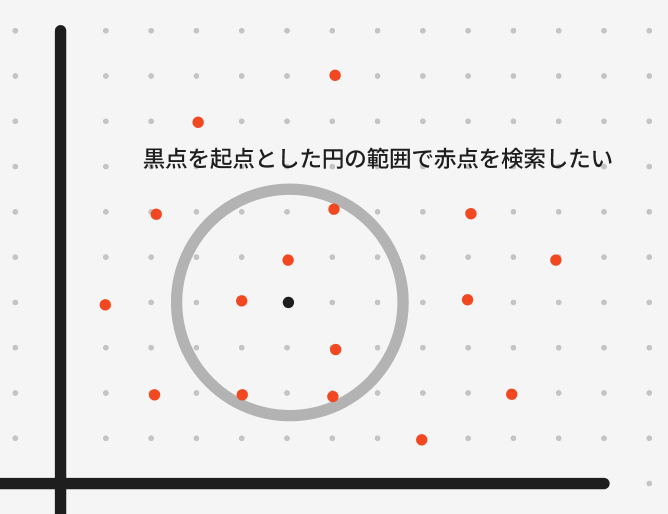
図で表すと、以下のようなイメージです。
黒い点が対象のお店を表すデータとしてます。そのお店の詳細ページを表示する際に、半径数km以内で同じジャンルのお店(図でいうと赤い点)を取得するという仕様です。
このようなデータの取得をするSQLも、スロークエリログの中に確認できました。
SQLは以下のようになっていました。
SELECT
id,
x,
y,
SQRT(POWER(x - :target_x, 2) + POWER(y - :target_y, 2)) AS distance
FROM points
WHERE id <> :target_id
HAVING distance <= :radius;テーブル名やカラム名は実際のものから変えています。xとyはそれぞれx座標とy座標を表していて、2つの組み合わせで位置が決まります。target_idは、対象のデータのidで、図でいうところの黒点のデータのidです。target_xとtarget_yは黒点のデータのx座標とy座標を表します。radiusは円の半径を表していて、どこまで近い距離で取得したいかを表します。
※ここでは、SELECT句で計算した distance を条件に使うため、WHERE句ではなくHAVING句で絞り込んでいます。
上記のSQLの場合、まず黒点以外の全てのデータ(図でいうと赤点のデータ)を取得し、その後に黒点のデータとの距離を計算し、その後HAVINGで距離が近いデータを絞り込むという動きになります。意図したデータは取得できるものの、赤い点のデータ件数が多くなればなるほど、処理は重くなります。仮にデータが数万件あり、近くのデータとしてヒットするのは10件程度だとするなら、大半のデータを無駄に取得して距離を計算していることになります。
改善策としては、WHERE句で先に絞り込むようにします。
そのためには、xとyのカラムにインデックスを設定する必要があります。
xとyのカラムに対してマルチカラムインデックスを設定することで、xとyそれぞれにBETWEENで絞り込む際にインデックスが効くようになり、絞り込みで実行コストを抑えることができるようになります。
なお、マルチカラムインデックスは先頭カラム(この場合は x)の絞り込みが特に重要です。
SELECT
id,
x,
y,
SQRT(POWER(x - :target_x, 2) + POWER(y - :target_y, 2)) AS distance
FROM points
WHERE
x BETWEEN :target_x - :radius AND :target_x + :radius
AND y BETWEEN :target_y - :radius AND :target_y + :radius
AND SQRT(POWER(x - :target_x, 2) + POWER(y - :target_y, 2)) <= :radius;今回、話を単純化するためにx座標y座標で位置を表現しましたが、実際の業務では緯度と経度でデータを保持しており、距離の計算はもう少し複雑です。(ここでは深入りしませんが、興味があれば調べてみてください。)
また、今回は使用していませんが、緯度と経度による位置情報を扱う場合MySQLでは空間インデックスという仕組みが使用できるので、こちらも検討してみると良いでしょう。
ページ遷移ごとに全件データを取得している
スロークエリログの中に、時々以下のようなcount関数を使ったSQLも確認できました。
SELECT
count(1) as cnt
FROM
tableA a
WHERE
exists (SELECT id FROM tableB a_id = a.id)
AND
...これは、アプリの中で扱っている対象のリソースデータに対して、有効とみなせるデータを取得しているのですが、画面構成上、ヘッダーにこの件数を取得しており、画面遷移の度に有効データ毎回取得していました。SPAで構築されたWebアプリであれば、ヘッダーを表示する際に一度だけ件数を取得できればいいため、あまり問題にはなりませんが、今回対象にしていたWebアプリはSPAではなかったため、画面遷移ごとに毎回同じデータを取得していました。
画面遷移の度に毎回スロークエリログに流れるわけではありませんでしたが、まれにスロークエリに該当する速度になります。このような件数の取得は、データ件数が多くなればなるほど必然的に遅くなり、インデックスやSQLの書き方での改善には限界があります。
しかし、データの件数が頻繁に変わるものでなければ、あらかじめ集計結果を別で保存しておくことで改善が見込めます。実際、対象のWebアプリではリソースデータは日次バッチ処理により更新されるものだったので、サマリ用のテーブルを作って同じバッチ処理のタイミングで集計結果を保持することで、画面遷移の度にcountによる集計のコストをかけずに済みます。Redisなどのインメモリデータベースをも併用して使っているのであれば、そこに格納しておくことでより高速化が図れるでしょう。残念ながらMySQLでは使用できませんが、PostgreSQLなどを使っているのであれば、マテリアライズドビューを使って、集計結果を参照できるビューを作成しておくのも良さそうです。
また、単純に画面表示を速くしたいという事であれば、件数の取得処理を非同期処理にし、画面表示後に取得するようにすることで、SQLの速度はそのままにユーザー体験の向上を図れます。(確認したらアプリ側では非同期の取得にはしていたようです)
どのような解決策が最適なのかはアプリケーションの性質やアーキテクチャによるところですが、様々な案のなかから実装コストなどを加味して検討すると良いでしょう。
まとめ
- パフォーマンス改善はまずボトルネックを探す
- DBのスロークエリログを有効に活用する
- ヒント句は本当に必要な場面以外では使用しない
- インデックスが使われるSQLの書き方を知る
- データ件数が多い場合、先に絞り込みをしてから計算処理をする
- 集計結果を頻繁に使用する場合、あらかじめ別のテーブルに保存したり、キャッシュすることで改善する
- 画面表示などのユーザー体験を向上させたい場合は非同期や遅延読み込みを活用する